基于索引增强(RAG)下的开发理论及总结
1. 前言
目前RAG还形成不了传统意义上的开发范式,它是类似一个应用的框架或者开发思维,是一种结合外部知识检索(Indexing/Retrieval)和语言生成模型(LLM)的方法,用于提高生成回答的实时性和上下文相关性,是解决大语言幻觉的工具。
2. 大语言幻觉
大语言会出现幻觉,存在事实性幻觉和忠实性幻觉,表现为对事实的捏造、事实不一致、偏离用户指令、上下文不一致、逻辑不一致等
2.1 产生的原因
产生幻觉的原因可以分为以下三大来源:数据源——>训练过程——>推理
- 数据是大模型的粮食,错误信息和偏见的输入,大模型本身存在的知识边界,一些过时的事实知识
- 在模型的预训练阶段:前一个token预测下一个token,随着token的增长导致注意力被稀释,错误的token也会导致发生联级错误
- 在模型的对齐阶段:标注的数据超出了大语言本身的能力,会被训练会为超过边界的知识内容,从而放大了幻觉。二是模型的倾向迎合人类的偏好,从而牺牲了信息的真实性
- 推理导致的幻觉:由于推理是概率生成,上下文关注不足,例如softmax瓶颈都会导致生成偏差
⭐️从涌现/创新的角度,大语言产生的幻觉不会彻底被解决,如果失去了幻觉,那么大语言模型就无法成长,成为一个只能读取老旧数据的仓储
2.2 幻觉的缓解
缓解幻觉的方案有很多比如:涵盖调整模型参数、外挂知识、多智能体互动、加入诚实样本
其实最好的方式就是直接使用收集高质量的事实数据,并消除数据的偏见,并且在训练、对齐、推理阶段做模型本身的调整,但是一般这样的方式成本很高
所以这里就引入了RAG(索引增强生成),没错RAG是比较低级(低成本)的一种解决方案,但是它对开发出预期的应用很有效。
3. RAG简述
3.1 什么是RAG
索引增强生成(RAG)是在大模型生成响应之前,引用训练数据之外的权威知识库,对原有训练数据的扩展,所以不用重新训练模型的情况下,可以保持回答的相关性、准确性和实用性。
简单理解就是:在发起提问之前,先从外部检索对应的知识,和用户的提问一起构成Prompt,再让LLM生成内容。
其实到目前为止,主流的大模型已经可以直接或者间接,通过爬取网页的数据、Function Call、MCP来增强自己,详见ChatGPT 工具->搜索网页
3.1 RAG的类型
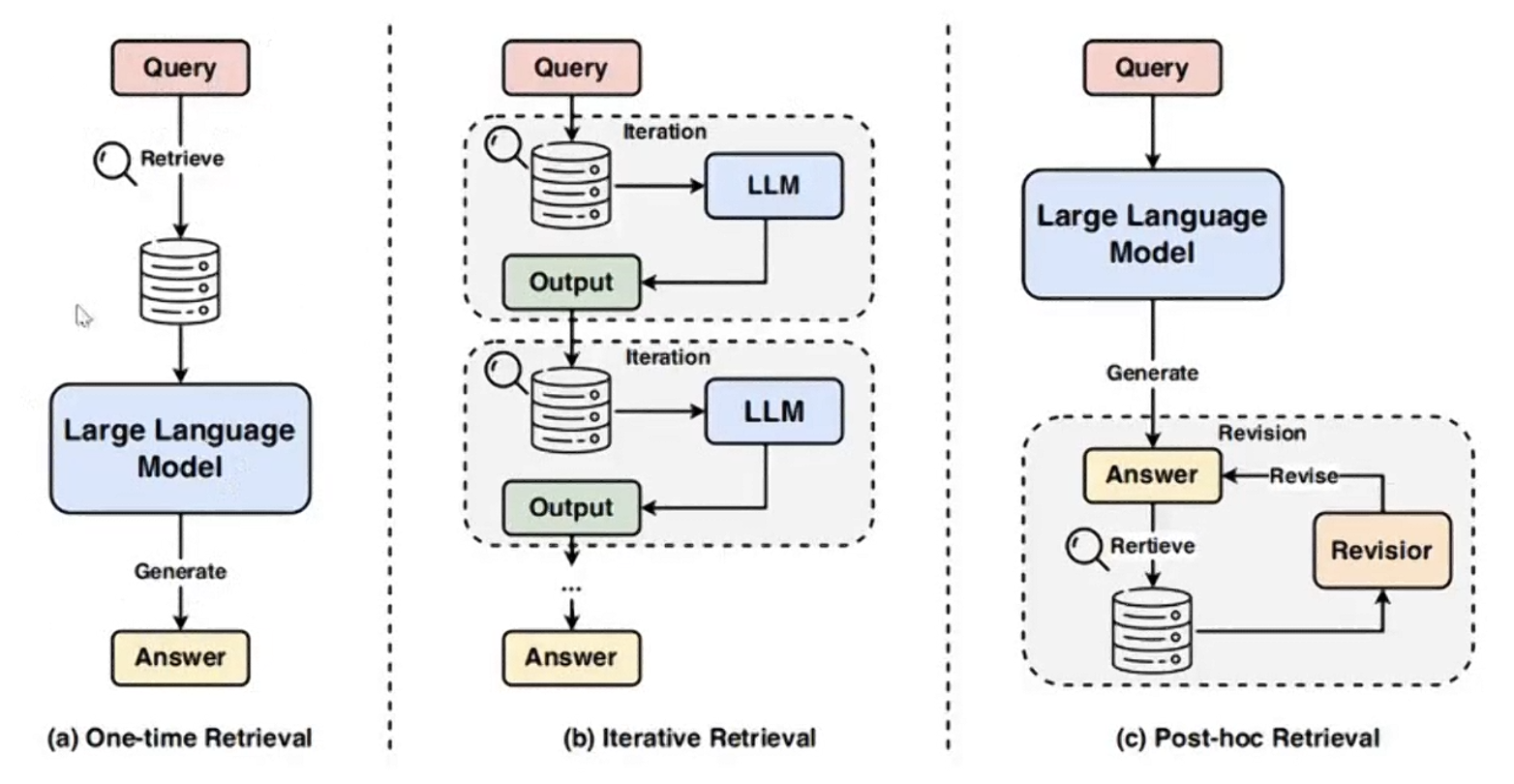
a) 一次性检索,b) 迭代索引,c) 事后索引
现在主流的方式是使用一次性检索
4. 原理流程图
如下:
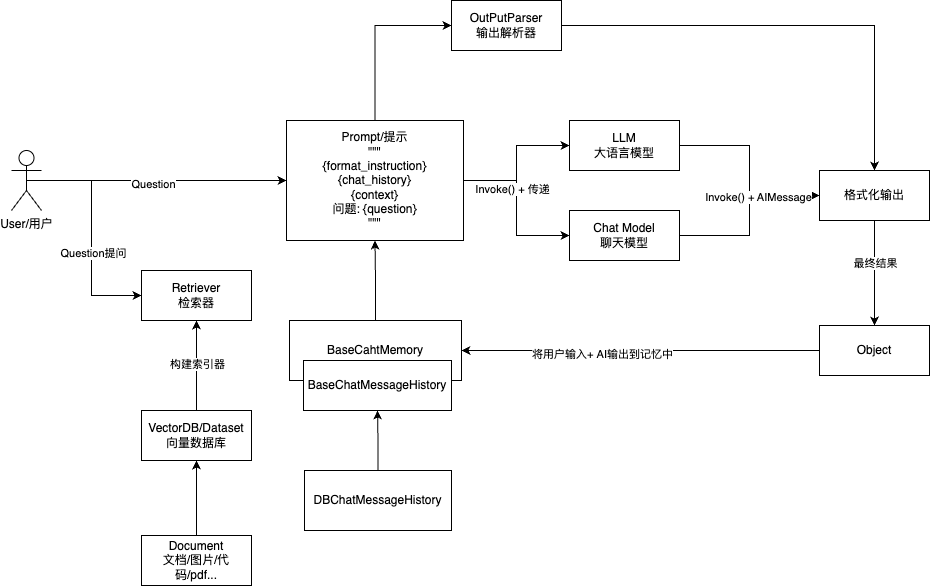
实际在代码中,无论多么复杂的 RAG、无论如何进行 RAG 优化,**本质上都是执行外部检索,然后将外部检索的内容和用户原始提问合并成最终 Prompt,再向大语言模型发起提问,最终得到对应的内容 **。
5. RAG开发优化策略
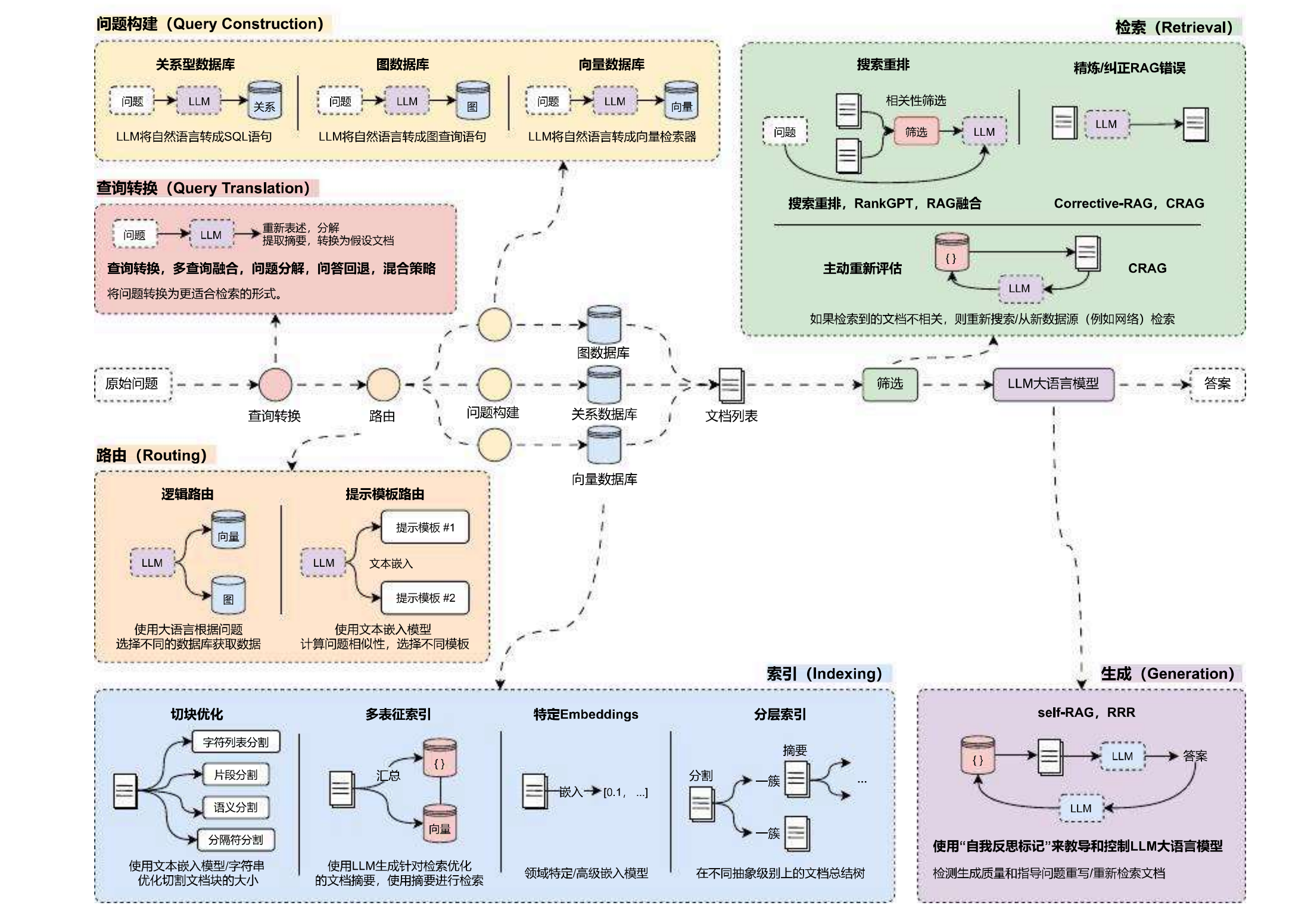
在RAG开发的6个阶段中,不同的阶段拥有不同的优化策略,需要针对不同的应用进行特定性的优化,
目前市面上常见的优化方案有:问题转换、多路召回、混合检索、搜索重排、动态路由、图查询、问题重建、自检索等数十种优化策略,每种策略所在的阶段并不一致,效果也有差异,并且相互影响。
并且RAG优化和LangChain并没有关系,无论使用任何框架、任何编程语言,进行RAG开发时,掌握优化的思路才是最重要的!
将对应的优化策略整理到RAG运行流程中,优化策略与开发阶段对应图如下:
6. 专业词汇
DocumentLoader: 文档加载、转化器
词分割器、语义分割器
Embedding:嵌入转化向量
vectorStore 向量数据库
Retriever检索又名召回
prompt提示词